Replicação de dados e manutenção de consistência.
Uma apresentação sobre disponibilidade, latência, consistência e conflitos em sistemas distribuídos.
Quatro objetivos e uma dificuldade.
Disponibilidade
Continuar rodando quando máquinas ou datacenters falham.
Operação desconectada
Permitir trabalho durante interrupções de rede.
Latência
Colocar dados mais perto dos usuários.
Escala de leitura
Distribuir reads entre réplicas.
Dificuldade Toda escrita precisa chegar às réplicas, mesmo com atrasos, falhas e concorrência.
Mudanças nos dados ocorrem em redes sujeitas a atraso e falhas de nós.
write
ordem importa
replicação
pode atrasar
read
pode observar versão anterior
Discussão
Se uma escrita foi confirmada ao cliente, mas ainda não chegou a outras réplicas, o que deve acontecer quando o líder falha?
Single-leader tem menor complexidade conceitual, com risco de leituras atrasadas.
- Writes vão para o líder.
- Followers reaplicam o log de mudanças.
- Reads podem ir a qualquer réplica.
A ordenação das escritas é centralizada, reduzindo conflitos de escrita.
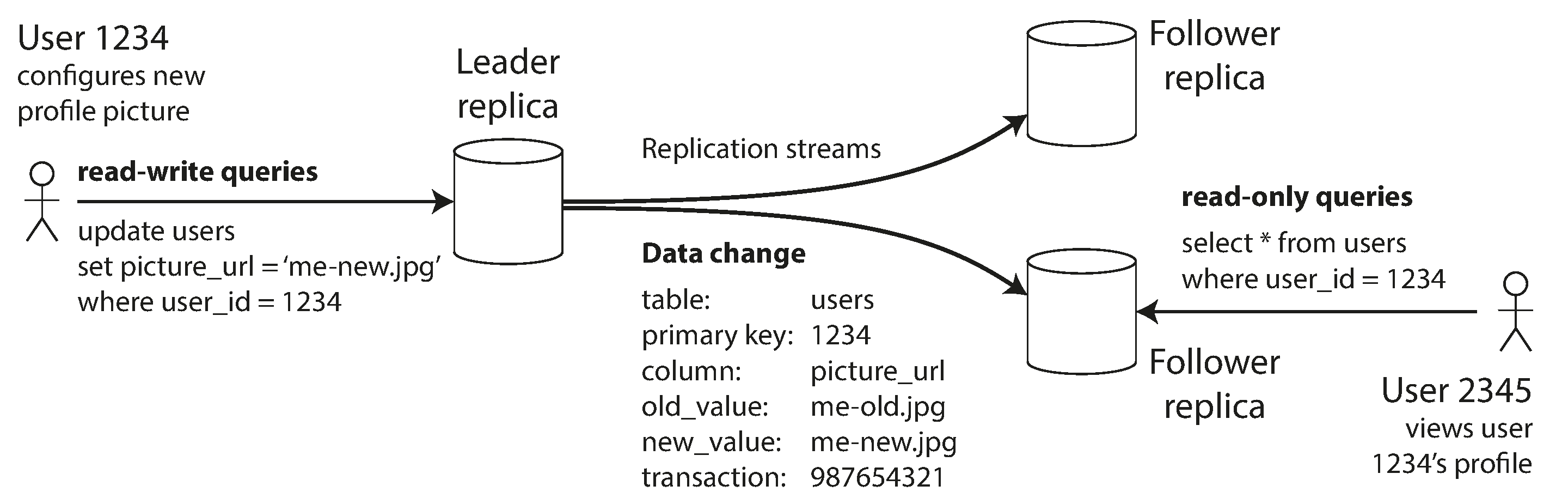
Figura 5-1, replicação baseada em líder.
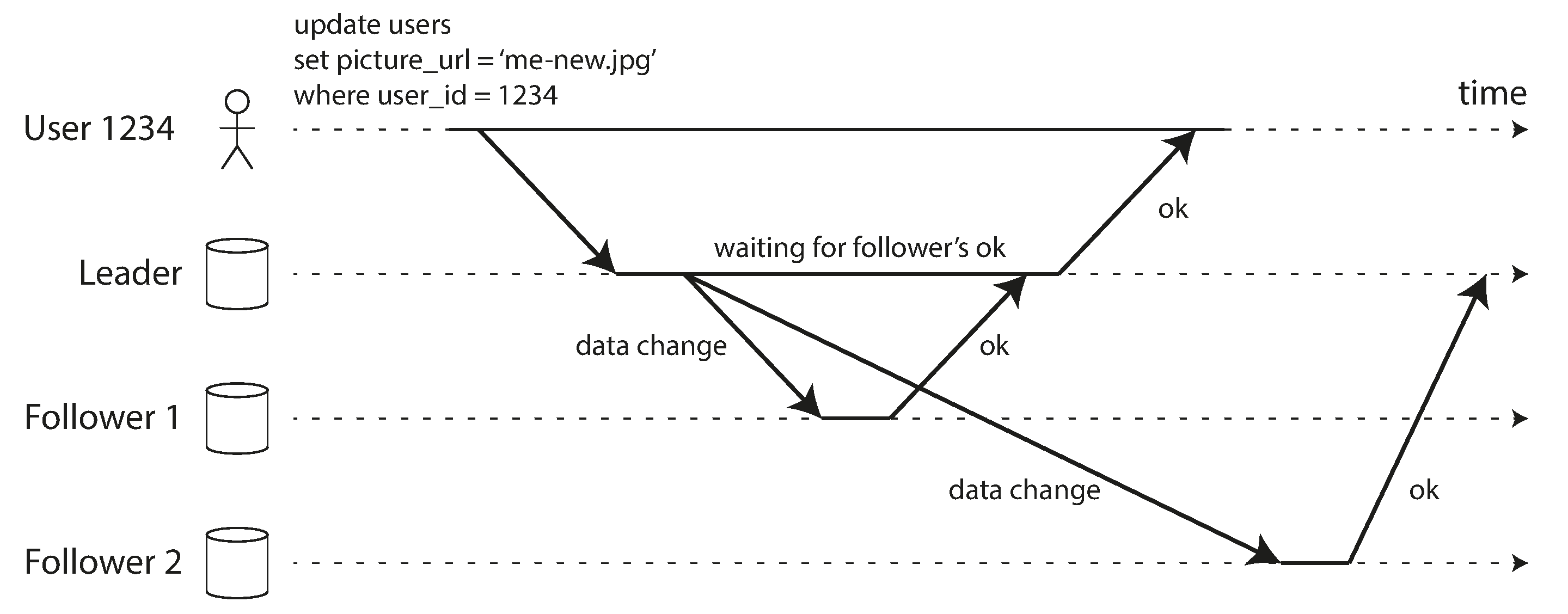
Figura 5-2, um follower síncrono e outro assíncrono.
A confirmação ao cliente determina o comportamento sob falha.
Síncrono
Maior garantia de cópia atualizada; pode bloquear writes se a réplica não responder.
Assíncrono
Baixa latência em operação normal; lag pode crescer e failover pode perder writes recentes.
Read-after-write exige que o usuário observe as próprias escritas.
Caso de anomalia com escrita no líder seguida de leitura em réplica stale.
Regras possíveis incluem leitura no líder para dados do próprio usuário, timestamps/versionamento ou sessão fixada em réplica fresca.
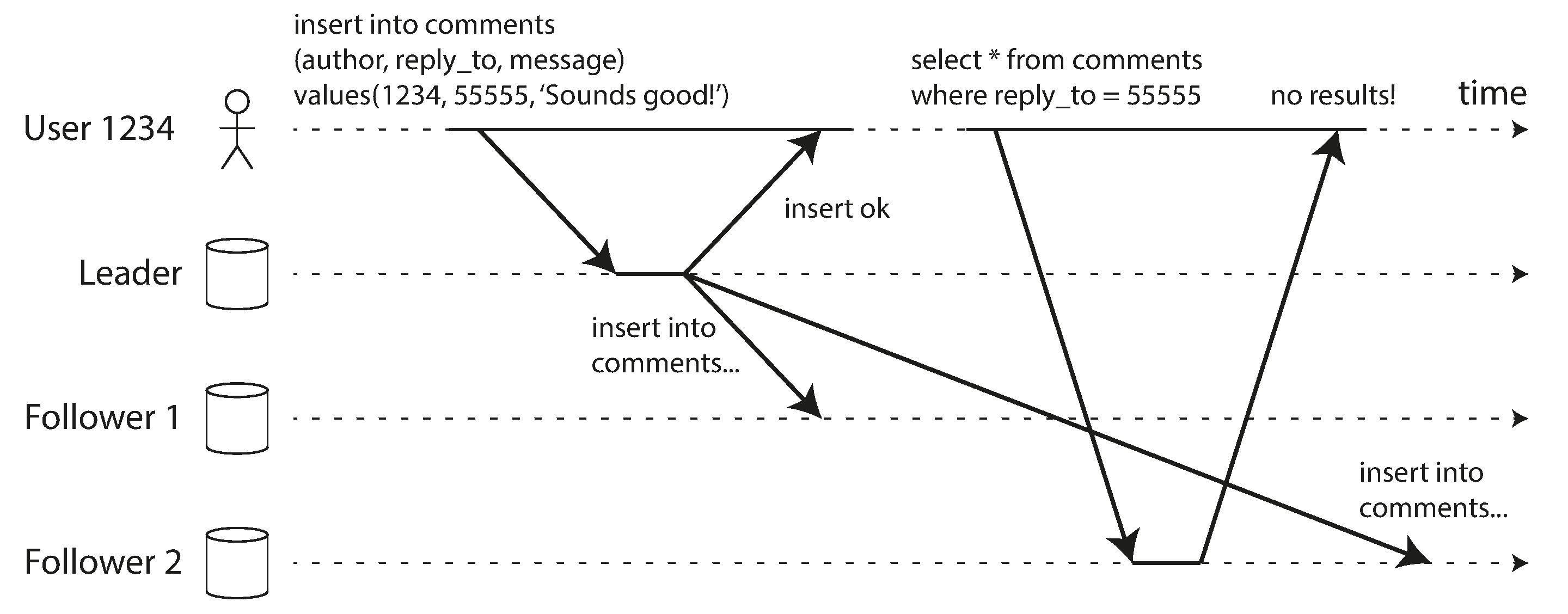
Figura 5-3, read-after-write consistency.
Consistência também envolve a ordem observada pelo usuário.
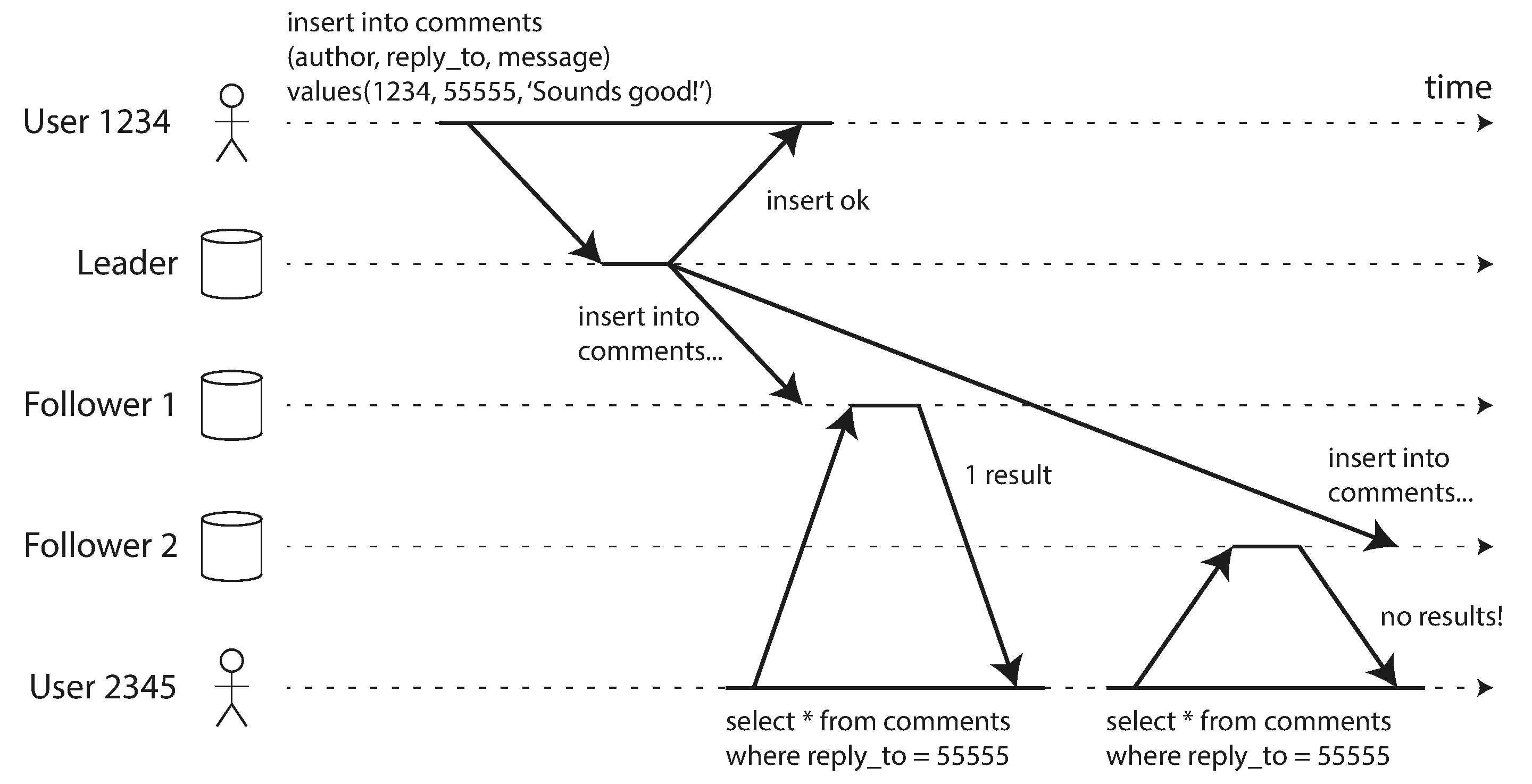
Figura 5-4, leituras monotônicas.
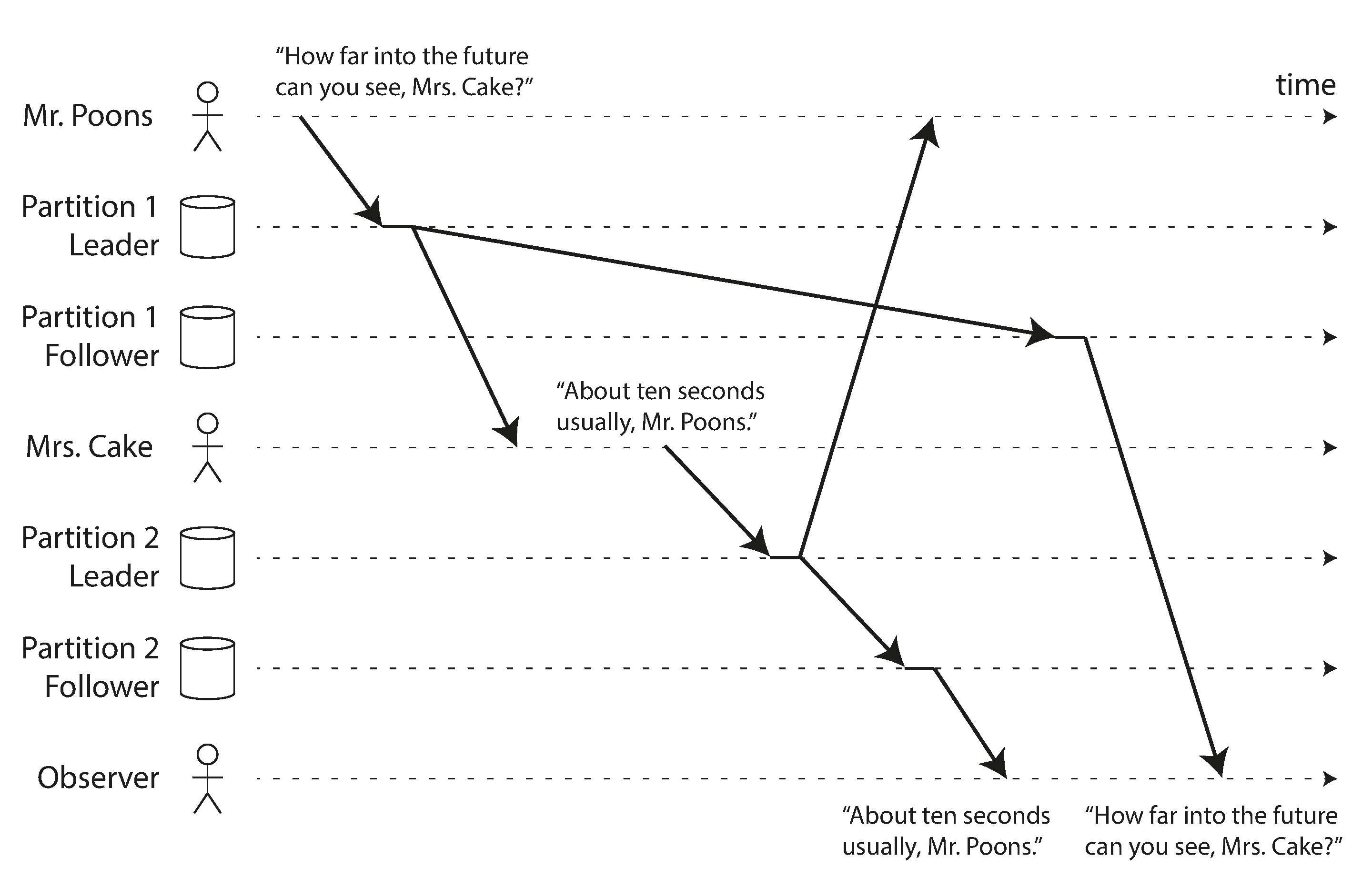
Figura 5-5, prefixo consistente.
Monotonic reads
Após observar uma versão nova, leituras posteriores não devem mostrar estado anterior.
Consistent prefix reads
Se B depende de A, a leitura não deve apresentar B antes de A.
Três famílias de replicação com custos distintos.
| Modelo | Write entra onde? | Força | Custo |
|---|---|---|---|
| Single-leader | Um líder | Ordem simples; ausência de conflito de escrita entre líderes. | Failover e reads stale. |
| Multi-leader | Vários líderes | Boa latência local e operação entre datacenters. | Conflitos e topologias difíceis. |
| Leaderless | Várias réplicas | Tolerância a falhas via quórum. | Consistência fraca e resolução de versões. |
Multi-leader usa writes locais com reconciliação global.
- Vários líderes aceitam escrita.
- Cada datacenter pode servir usuários próximos.
- Conflitos deixam de ser exceção distante.
Maior disponibilidade e menor latência podem exigir garantias de consistência mais fracas.
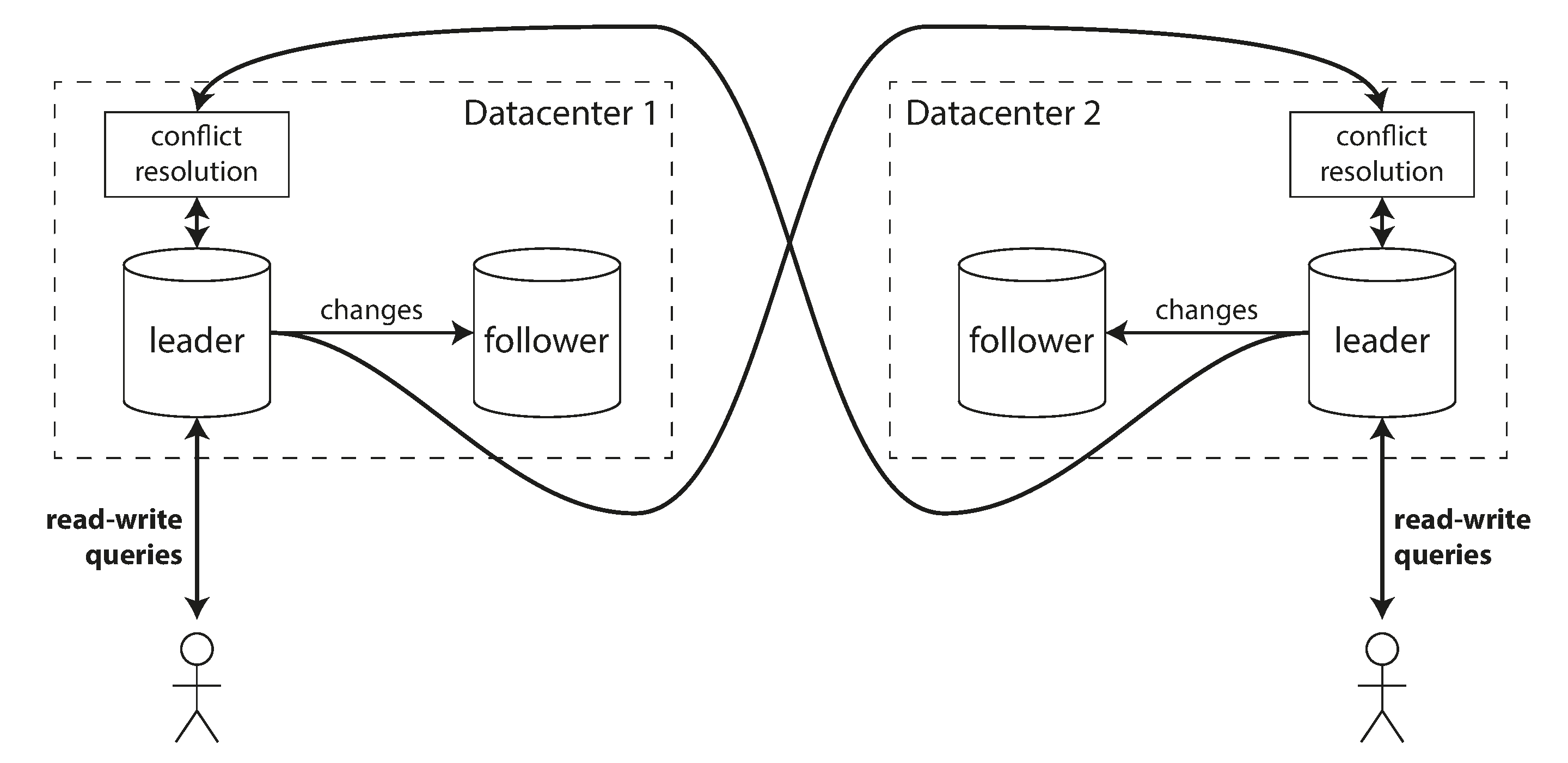
Figura 5-6, replicação multi-leader entre datacenters.
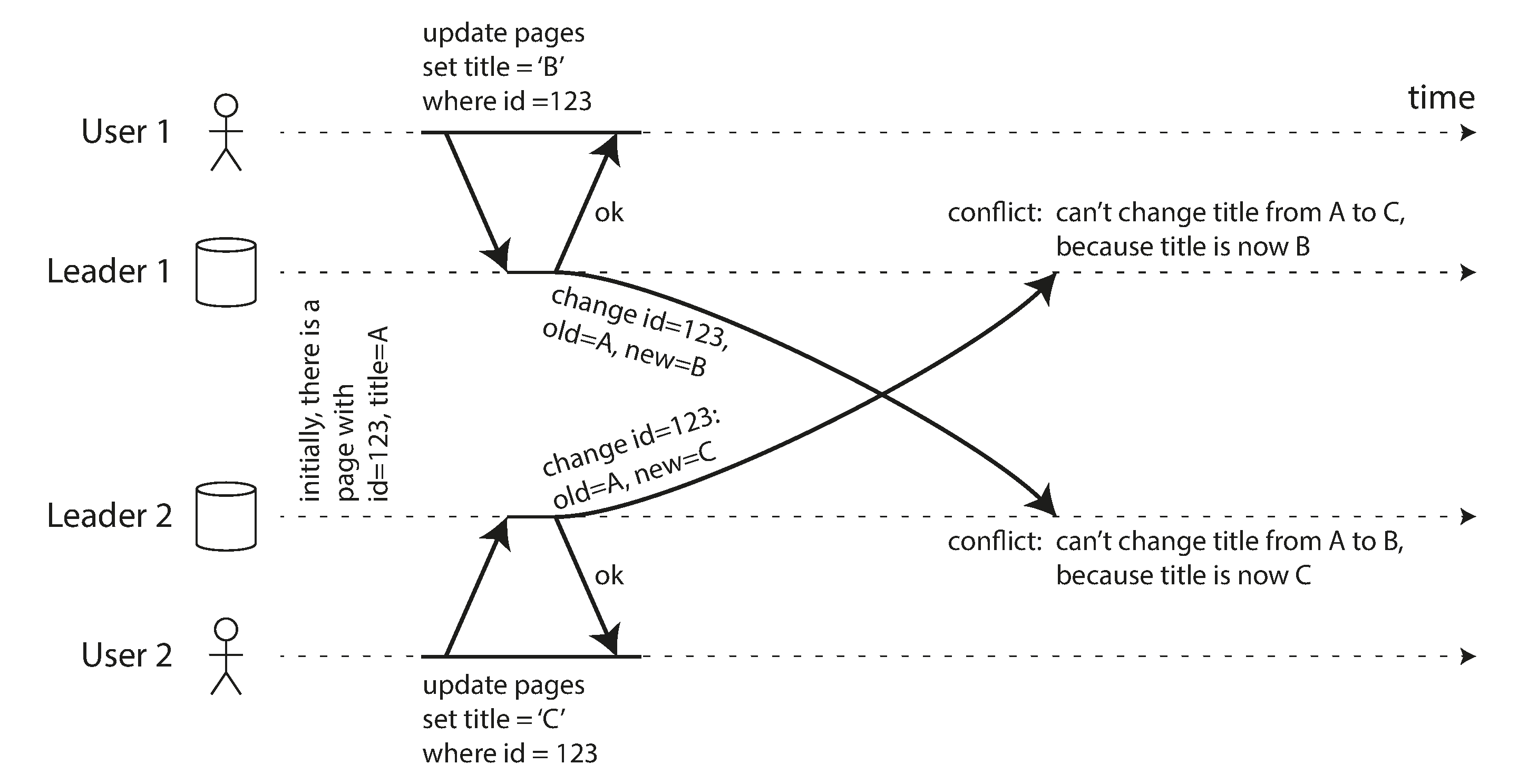
Figura 5-7, dois líderes atualizam o mesmo registro concorrentemente.
Sem ordem única, o conflito precisa ser preservado ou resolvido.
Problema
Líder 1 aceita A para B; líder 2 aceita A para C. Um líder não observou a escrita do outro.
Pergunta
O banco deve escolher, preservar as duas versões ou delegar para a aplicação?
O caminho da mensagem afeta a ordem observada.
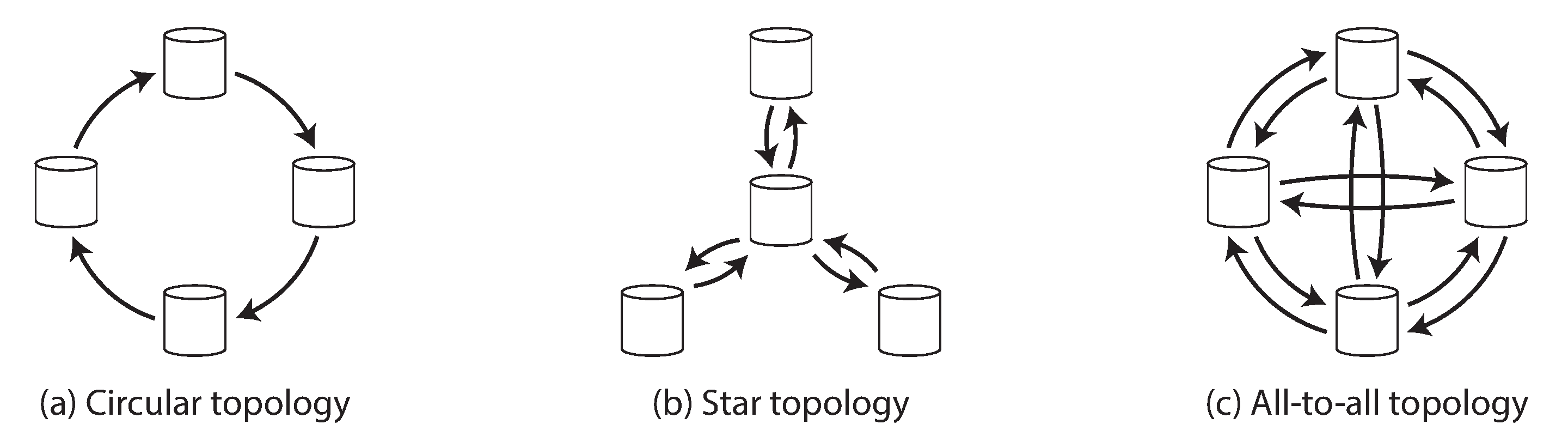
Figura 5-8, circular, estrela e all-to-all.
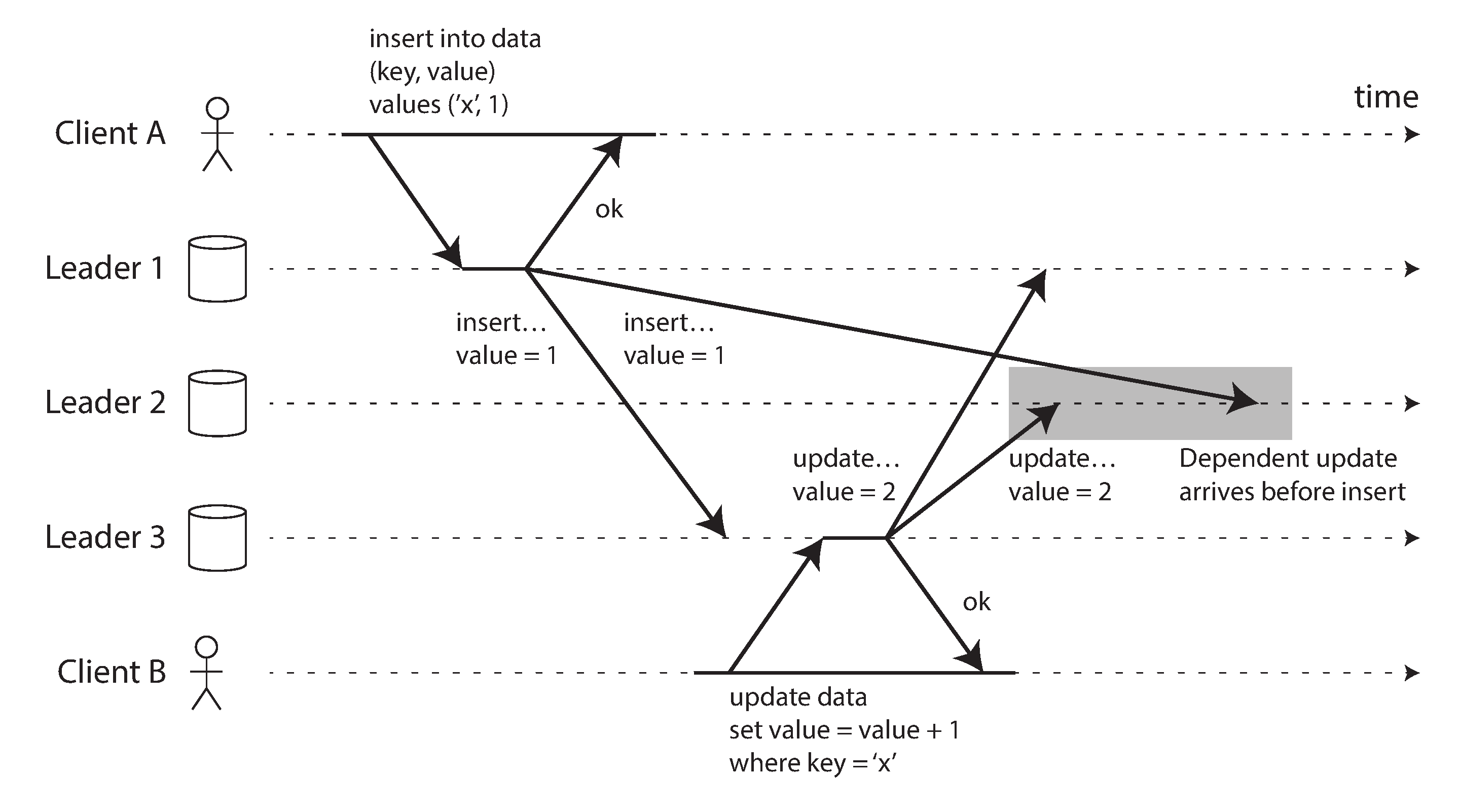
Figura 5-9, mensagens podem chegar fora de ordem.
Circular
Simples, mas um nó pode interromper propagação.
Estrela
Centraliza caminho; o centro vira ponto sensível.
All-to-all
Mais direto; exige tratamento de ordem e duplicidade.
Leaderless faz o cliente conversar com várias réplicas.
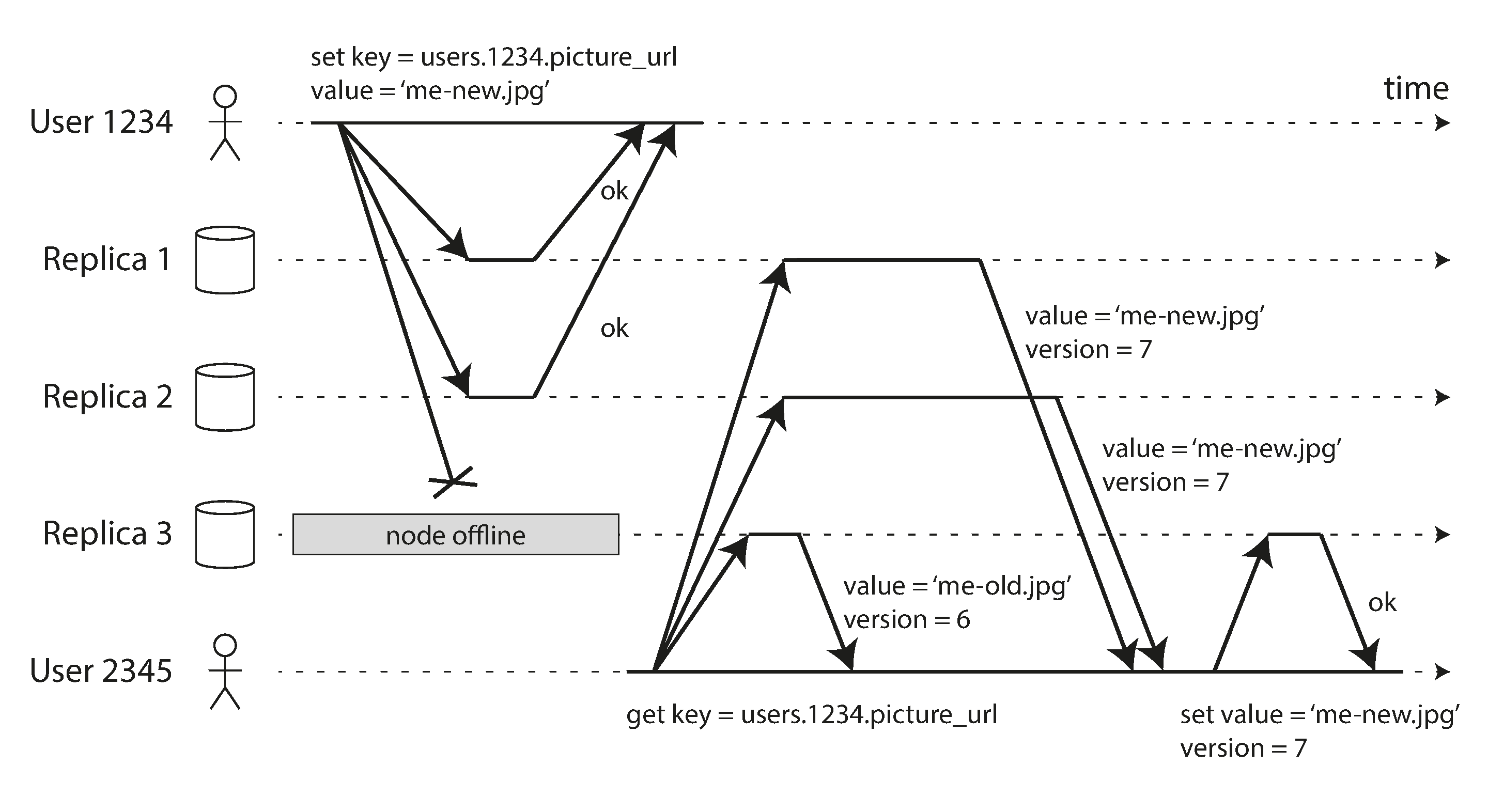
Figura 5-10, write/read por quórum e read repair.
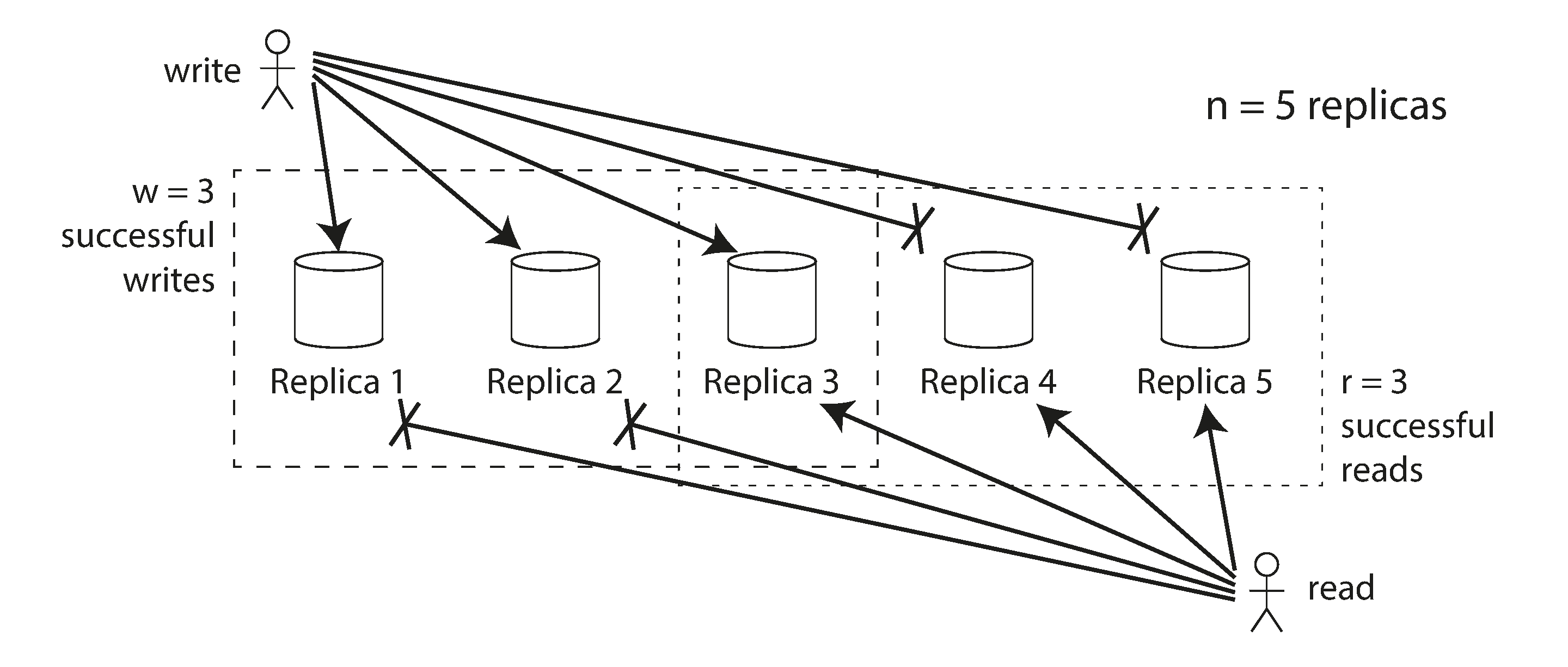
Figura 5-11, se w + r > n, os quóruns se cruzam.
Ponto principal Ler de várias réplicas ajuda a detectar valores stale; escrever em várias réplicas ajuda a sobreviver a falhas.
Réplicas stale precisam ser detectadas e atualizadas.
Read repair
Durante uma leitura, o cliente percebe versões antigas e atualiza a réplica stale.
Anti-entropy
Processos de fundo procuram diferenças e copiam dados faltantes.
Sloppy quorum
Em falhas de rede, nós fora do conjunto original podem aumentar disponibilidade.
Hinted handoff
Quando o nó correto volta, as escritas temporariamente aceitas são entregues.
Ponto para discussão
Quórum reduz a chance de ler dado antigo, mas não elimina todos os cenários de inconsistência em sistemas reais.
Sem líder, “último valor” pode não estar bem definido.
Atrasos variáveis fazem réplicas discordarem sobre qual escrita venceu.
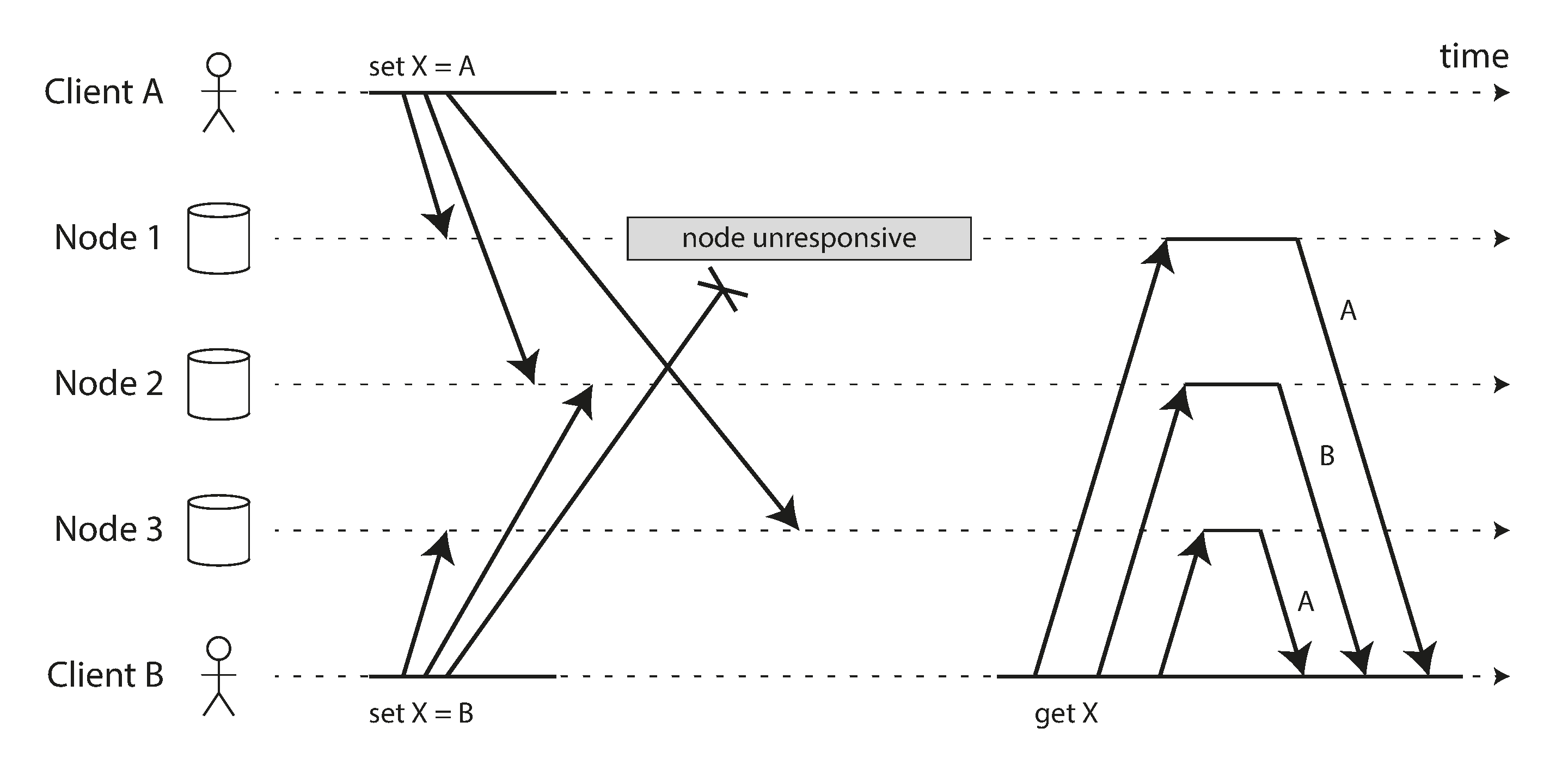
Figura 5-12, writes concorrentes em datastore estilo Dynamo.
Antes da resolução, é preciso identificar concorrência.
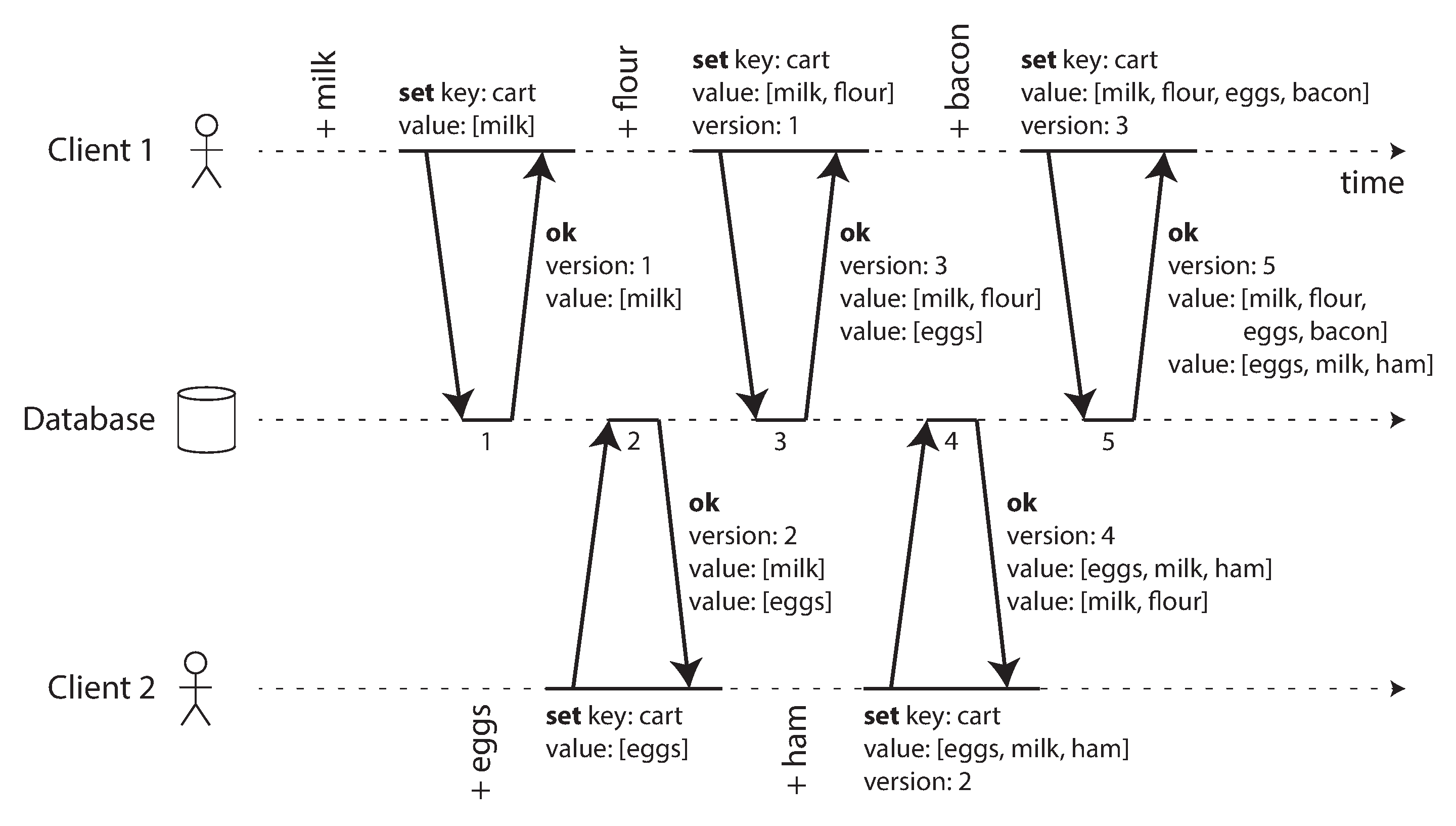
Figura 5-13, dependências causais em edições concorrentes.
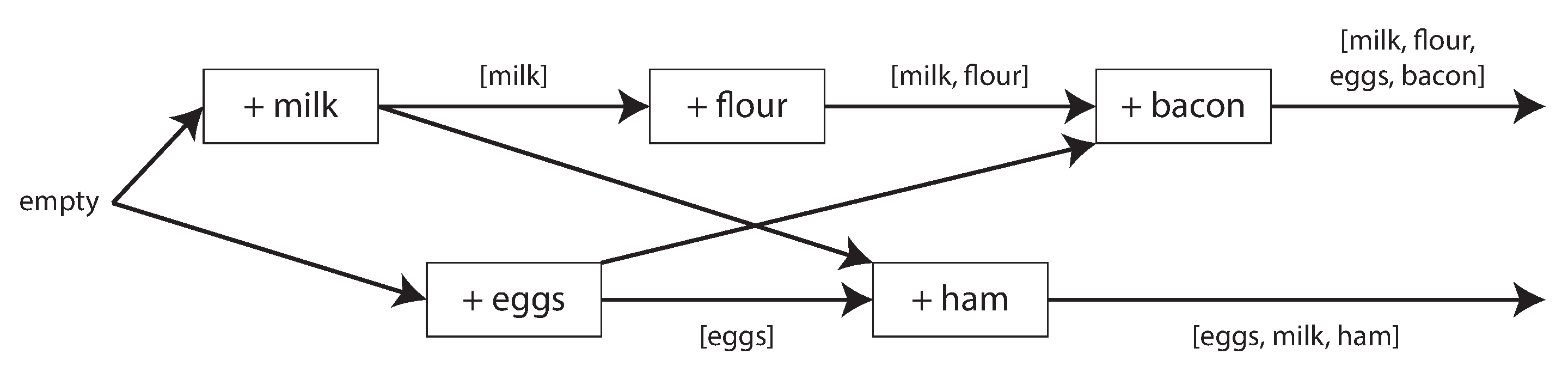
Figura 5-14, grafo de dependências causais.
Happened-before
Se uma operação observou a outra, há ordem causal.
Concorrente
As operações não observaram uma à outra.
Version vectors
Generalizam versionamento por réplica para rastrear dependências.
A escolha técnica define uma regra de produto.
Last write wins
Simples, mas pode descartar atualizações concorrentes.
Merge
Preserva informação quando a regra do domínio permite, como união de itens de carrinho.
Aplicação
Algumas decisões exigem semântica do domínio e interação com usuário.
Replicação desloca decisões difíceis para pontos específicos do sistema.
O capítulo apresenta critérios para formular trade-offs de replicação.
Se você quer simplicidade
Single-leader reduz conflitos, mas exige considerar lag, failover e stale reads.
Se você quer escrita em vários lugares
Multi-leader e leaderless aumentam tolerância operacional, mas enfraquecem garantias e exigem resolução de conflito.
Síntese Replicação mantém cópias; consistência define o que uma leitura pode observar.
O próximo tópico no livro é particionamento, que divide o dataset em vez de copiar o dataset inteiro.