Capítulo 3, Designing Data-Intensive Applications
Aviso: Este resumo foi gerado por IA usando como entrada o áudio transcrito da reunião.
Me ajude a gerar um relatório desta reunião de estudos que teve como foco
discussão do capitulo 3 (Storage and Retrieval) do
livro Designing Data Intensive Applications.
A transcrição está no arquivo "transcript.txt" no diretório atual.
Você deve criar um documento com os seguintes pontos:
1. Resumo (cerca de 300 palavras)
2. Principais tópicos debatidos (até 10)
3. Principais questões levantadas (ex. "Como gerenciar rollback em sistemas
com muitos usuários?")
4. Exemplos utilizados para ilustrar os conceitos abordados
Foque apenas na parte que diz respeito ao estudo do livro. Ignore discussões prévias sobre outros assuntos.A reunião técnica concentrou-se na discussão do capítulo 3, com foco em como bancos de dados armazenam e recuperam dados de forma eficiente em diferentes cenários de carga. O grupo começou diferenciando padrões de uso: em OLTP, predominam muitas operações curtas sobre pequenos subconjuntos de dados, com forte dependência de índices e garantias transacionais; em OLAP, as consultas percorrem grandes volumes para agregações, e o gargalo tende a ser a largura de banda de leitura do disco para memória.
A discussão avançou para os dois grandes modelos do capítulo:
estruturas log-structured (incluindo LSM-trees) e B-trees. Foi
enfatizado que log-structured favorece escrita rápida por
append sequencial, enquanto B-trees tendem a favorecer
atualizações e leituras pontuais com estrutura já organizada para busca.
Em seguida, o grupo explorou um exemplo didático de banco chave-valor em
arquivo com operações get/set, destacando riscos de
corrupção em interrupções de escrita e a necessidade de compactação.
Para desempenho de leitura, discutiu-se o uso de índice em memória (hash index) mapeando chave para offset no arquivo, evitando varredura linear. A partir daí, foi detalhado o ciclo MemTable → SSTable: escrita inicial em estrutura ordenada em memória (árvore balanceada), persistência em SSTable ao atingir limite, manutenção de múltiplos segmentos e execução de merge/compaction em background para remover versões antigas e reduzir fragmentação.
Também foram abordados Bloom filters (checagem probabilística de existência), índices esparsos e blocos comprimíveis para diminuir I/O, além de armazenamento por linha versus por coluna e seus impactos em consultas transacionais e analíticas. Houve ainda ênfase no custo de manter consistência sob concorrência, no papel do cache para reduzir acessos ao disco e na diferença entre atualizar registros no lugar (update-in-place) e acumular versões para consolidação posterior.
Como encaminhamento, o grupo indicou continuidade do capítulo na reunião seguinte, com possibilidade de diagramas para consolidar os fluxos de leitura/escrita.
get/set) como modelo
didático.get e
set.Aviso: Este resumo foi gerado por IA usando como entrada o áudio transcrito da reunião.
Gere um relatório desta reunião de estudos que teve como foco
discussão do capitulo 3 (Storage and Retrieval) do
livro Designing Data Intensive Applications.
A transcrição está no arquivo "4-encontro-capt-3-pt-2.txt" no diretório atual.
Você deve criar um documento com os seguintes pontos:
1. Resumo (cerca de 300 palavras)
2. Principais tópicos debatidos e questões levantadas (até 10)
3. Exemplos utilizados para ilustrar os conceitos abordados (contidos no texto ou de
experiências profissionais dos participantes)
Foque apenas na parte que diz respeito ao estudo do livro. Ignore discussões prévias
sobre outros assuntos.
A reunião concentrou-se na discussão do Capítulo 3 de Designing Data-Intensive Applications, com foco nas estratégias de armazenamento e recuperação de dados e nos trade-offs entre diferentes estruturas de storage engine. O grupo iniciou retomando os conceitos vistos anteriormente sobre abordagens baseadas em log, especialmente LSM Trees e SSTables. Foram relembrados o papel da MemTable em memória, o flush para disco, o uso de Bloom Filters e índices esparsos para acelerar leituras, além da compactação/merge como mecanismo para reduzir a quantidade de SSTables e eliminar versões antigas de registros. Nessa retomada, ficou claro o contraste entre estruturas otimizadas para escrita e os custos adicionais que aparecem depois, principalmente na leitura e na manutenção de múltiplos arquivos em disco.
A partir disso, a conversa migrou para storage engines orientadas a atualização, com destaque para B-Trees. O grupo discutiu que esse modelo sacrifica parte da performance de escrita para ganhar eficiência na busca e atualização de registros já existentes. Também apareceu a distinção entre OLTP e OLAP, usada para mostrar que o padrão de acesso aos dados é decisivo na escolha de como armazená-los. Houve ênfase na ideia, defendida pelo livro, de que o desenvolvedor — e não apenas o DBA — precisa entender esses padrões para decidir sobre índices e otimizações.
Na parte central da reunião, os participantes exploraram índices como estruturas redundantes, separadas da tabela principal, que aceleram consultas ao custo de mais espaço em disco e mais trabalho em escrita. Compararam listas encadeadas ordenadas com árvores de busca, discutindo por que uma linked list continua limitada por uma navegação linear entre páginas. Em seguida, aprofundaram o funcionamento das B-Trees: balanceamento, profundidade pequena, busca logarítmica e capacidade de indexar grande volume de dados com poucos níveis. Ao final, discutiram diferentes formas de armazenar valores no índice, incluindo clustered indexes, covering indexes e menções a índices multicoluna, multidimensionais e fuzzy.
The way we store data is highly dependant on how we expect to read that data.
Databases can be split into two main categories, based on how we read from and write to them.
OLTP (On Line Transaction Processing) are most common to web developers: speciallized on handle large volumes of request, where each request tends to focus on a small subset of data, generally specific rows.
Each row is queried by an index and them updated individually. Operations that depend on each other (where a single failure means the set of operations should be reverted) are treated atomically in a transaction.
Disk seek time (when querying data that match exact parameters) is often the bottleneck.
OLAP (On Line Analytics Processing), in contrast, tend to focus on aggregation and summarization of a large volume of rows.
Since each query might scan through large portions of a table, indexing is generally less effective.
Disk bandwidth is often the bottleneck, with data warehouses optimizing for read in detriment of write time.
On the OLTP side, there are two main ways to structure storage engines.
Log-structured is a more recent development which is gaining popularity (why?).
It is based on performing sequential writes on files and then deleting obsolete files, without ever updating past writes, which results in higher write throughput.
Updating-in-place treats the disk as a set of fixed-size pages that can be overwritten.
B-trees are a popular way to index data that allows for quickly finding and replacing stale data.
The way that information is saved to disk can also affect how we access our data, and can be adapted to best fit our model.
In most OLTP databases, storage is row-oriented: in a relational database this means that values from the same table are stored next to each other in disk.
In a document database that would mean that an entire document would be stored as a contiguous sequence of bytes.
When processing analytical data, it might be better to storage data in a column-oriented way. This would mean that for each table the values would be split by column, and values from the same column would be stored close to each other in disk.
This would make queries such as
SELECT name, residency, hobby FROM users more straight
forward.
Discuss!
Referência: https://use-the-index-luke.com/sql/preface.
Nós conversamos na última reunião sobre como a abstração do SQL vaza quando o desenvolvedor começa a pensar sobre performance.
Geralmente não pensamos em como a informação vai ser buscada no banco, e sim em qual informação queremos buscar.
SELECT date_of_birth
FROM employees
WHERE last_name = 'Garcia'Na medida em que o desenvolvedor precisa garantir requisitos de performance, ele precisa entender sobre como a informação é organizada no banco.
The abstraction reaches its limits when it comes to performance: the author of an SQL statement by definition does not care how the database executes the statement. Consequently, the author is not responsible for slow execution. However, experience proves the opposite; i.e., the author must know a little bit about the database to prevent performance problems.
A performance pode ser melhorada sem muito conhecimento de como os dados são salvos, nem de como a engine realiza as buscas (a implementação em C de um query do sqlite3, por exemplo).
O fator de maior impacto é o padrão de acesso aos dados. Conhecer como os dados são acessados é o que vai decidir, entre outras coisas, a escolha do tipo de storage (relacional vs. document oriented vs. vetorial).
Na maioria dos casos, quem possui esse conhecimento é justamente o desenvolvedor.
Referência: https://use-the-index-luke.com/sql/anatomy.
Um índice faz a consulta ficar rápida. Ele é uma estrutura distinta
da tabela onde ele age, criada com o comando create index,
que referencia a tabela.
Ele ocupa espaço no banco e possui uma cópia dos dados indexados da tabela alvo.
That means that an index is pure redundancy.
Buscar em um índice é como buscar um nome em uma lista telefonica ou palavras em um dicionário. O princípio fundamental é que elas vão estar organizadas em uma ordem conhecida.
A diferença é que o índice do banco está sempre sendo atualizado. Como os dados são ordenados, cada atualização envolve uma mudança nos dados já existentes.
O desafio da construção de índices eficientes é reduzir o impacto das escritas e atualizações redundantes quando os dados da tabela de referência são alterados.
Os bancos costumam usar duas estruturas de dado na solução desse problema: a doubly linked list e a search tree.
Reference: https://use-the-index-luke.com/sql/anatomy/the-leaf-nodes.
Os índices precisam manter uma ordem mas também permitir inserção de novos valores em qualquer lugar de forma rápida.
Os bancos usam listas duplamente encadeadas para desacoplar a ordem lógica dos elementos da sua ordem física na memória.
Cada elemento da lista é um database block (ou database page), que é o elemento de menor tamanho utilizado pelo banco, geralmente alguns kbs
Every table and index is stored as an array of pages of a fixed size (usually 8 kB, although a different page size can be selected when compiling the server).
O banco salva a maior quantidade possível de índices em cada página/bloco.
That means that the index order is maintained on two different levels: the index entries within each leaf node, and the leaf nodes among each other using a doubly linked list.
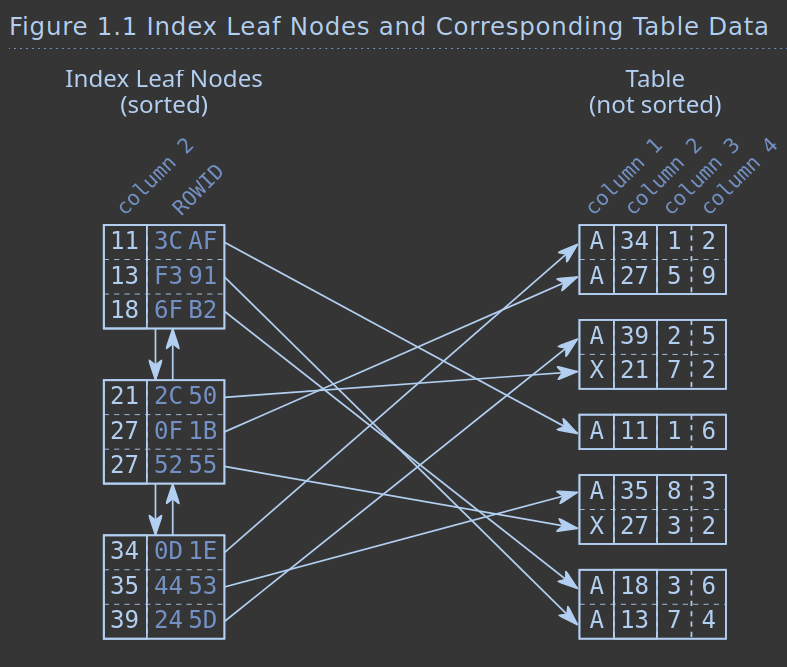
A imagem representa cada índice composto por dois valores: o valor da coluna, usado na ordenação (lado esquerdo) e o endereço da linha em memória, na direita.
Podemos imaginar que índices criados para colunas com tipos complexos são mais pesados.
A ilustração também mostra que, em bancos row oriented, todas as colunas de um mesmo row vão estar salvos de forma adjacente na memória: após encontrar um row baseado num índice, é fácil acessar suas outras colunas.
Discuss!
Se usassemos apenas a lista duplamente encadeada, mesmo sabendo que ela é ordenada, buscas ainda seriam demoradas, pois teriamos que ler os valores de um a um, partindo ou do início ou do fim da lista.
Para agilizar a busca, uma estrutura adicional é utilizada: a balanced search tree, a B-tree.
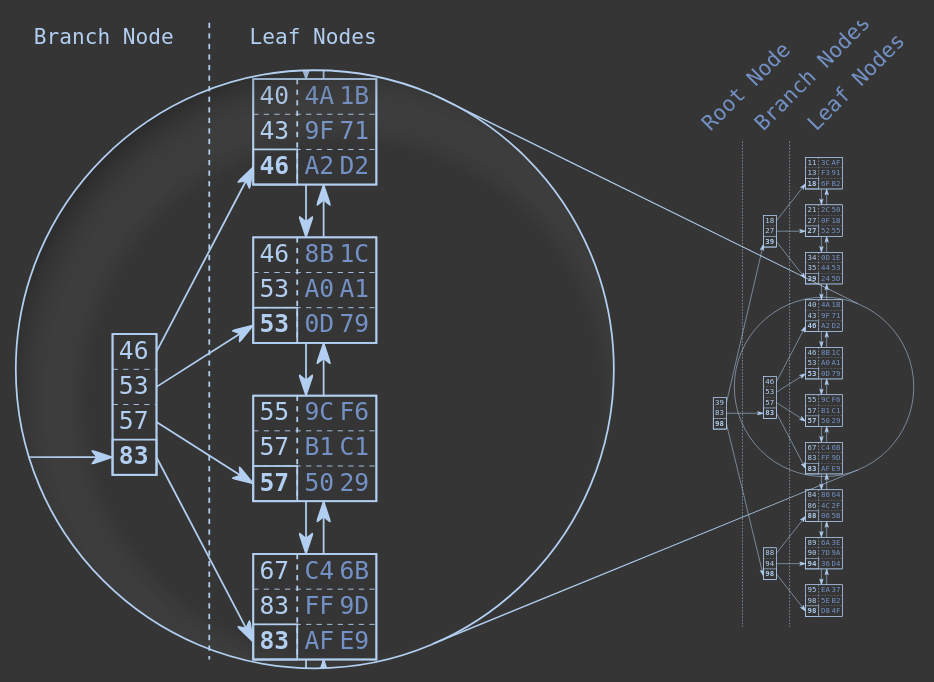
A lista encadeada estabelece a ordem entre os nós (leaf nodes), enquanto a B-tree relaciona diferente nós baseados no seu maior valor.
Essa estrutura permite realização de binary search nos dados, que possui O(log(n)).
A B-tree is a balanced tree—not a binary tree.
A estrutura é balanceada pois a profundidade (depth) da árvore é a mesma em todas as posições, além de crescer de forma logaritmica.
Discuss!
| Tree Depth | Index Entries |
|---|---|
| 3 | 64 |
| 4 | 256 |
| 5 | 1,024 |
| 6 | 4,096 |
| 7 | 16,384 |
| 8 | 65,536 |
| 9 | 262,144 |
| 10 | 1,048,576 |
Para um exemplo de quatro itens por nó, temos a quantidade acima de itens por nível de profundidade: bancos de dados podem guardar até centenas de itens por nó.
Nos exemplos anteriores assumimos que o índice é composto de dois elementos: uma chave (o valor da coluna indexada, usado na busca) e um valor (o endereço na memória da linha da tabela onde valor buscado está salvo).
Quando salvamos o endereço (ou referência), significa as linhas da tabela estão salvas em uma heap file, ou seja, sem ordem definida.
Referência (heaps): https://learn.microsoft.com/en-us/sql/relational-databases/indexes/heaps-tables-without-clustered-indexes?view=sql-server-ver17.
Esse formato é comum pois quando múltiplos índices são criados (por ex. um por coluna), a quantidade de dados duplicados é reduzido. Alterações nos valores também não precisam ser propagadas entre todos os índices.
O uso do heap file também faz sentido como forma de otimizar os writes: não precisamos alocar espaço de antemão, e a inserção de novas linhas geralmente acontece em qualquer lugar da memória que possua espaço livre.
Uma alternativa é salvar o valor inteiro da linha. Isso ajuda em situações onde precisamos otimizar ao máximo a performance dos reads (queremos evitar o lookup na memória para encontrar a linha referente ao índice).
Isso é chamado de clustered index. No MySQL, com a engine InnoDB, a chave primária é sempre um clustered index. Nesse caso, chaves secundárias podem apontar pro endereço da chave primária ao invés do endereço na heap file.
Chamamos de covering index quando apenas algumas colunas da tabela são duplicadas no índice. Assim, alguns queries são cobertos pelo índice, pois podem ser respondidos sem precisar fazer o lookup para a heapfile.
Discuss!
Follow up: como você trabalharia com queries baseados em intervalos?
SELECT * FROM restaurants WHERE latitute > 51.4946 AND latitude < 51.5079
AND longitude > -0.1162 AND longitude < -0.1004;